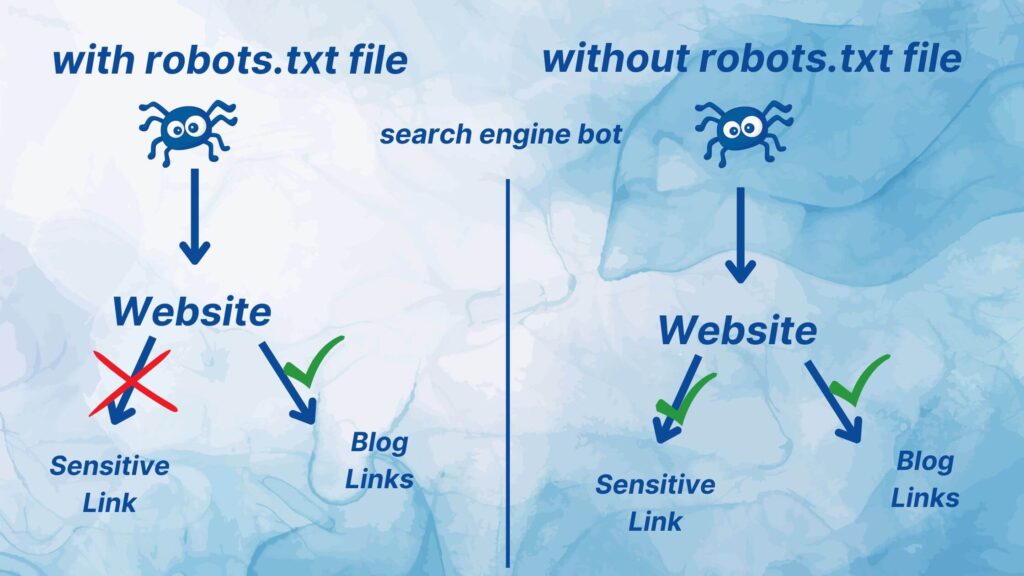
Before creating your robots.txt file first you need to understand and note down all those sensitive links which you don’t want to get crawled and indexed by search engines. I am saying this again and again because you won’t edit the robots.txt file on a frequent basis.
To create robots.txt and to understand the role of robots.txt we will create robots.txt from scratch.
There are also some websites that can create robots.txt file for free. We will talk about this later.
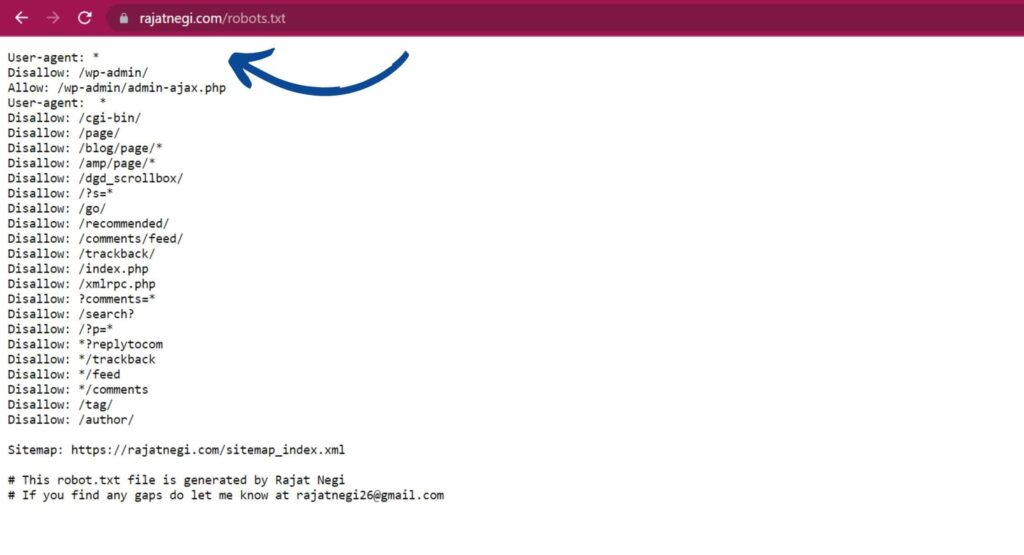
So, To create robots.txt file first you need to open a notepad, where you can write robots.txt syntax.
- User-agent, these are the crawlers and the in the robots.txt file we write
User-agent:*
This is to instruct all crawlers of search engines like Google, Yahoo and Bing.
For e.g If I write User-agent: Twitterbot
You can easily understand that the syntax is directly referring the Twitter’s Crawlers.
- Disallow, This syntax itself shows that it is for those pages which the website owner doesn’t want to index.
Disallow:
This is to instruct to all the crawlers not to crawl the page. So Crawlers are not going to crawl this page.
For e.g If I write Disallow: /media/
This means the website owner doesn’t want crawlers to crawl the media file which is at the backend of their website.
For e.g. I have a specific page on my website whose URL is https://www.rajatnegi.com/media/
And I write
Disallow: /media/
In the robots.txt file
Then the crawlers will not be going to crawl this page
To get to the role of robotst.txt you need to understand the syntax of disallow robots.txt
- Allow, This syntax is used to allow crawlers to crwal that page which you have blocked using a command like Disallow:
Allow :/
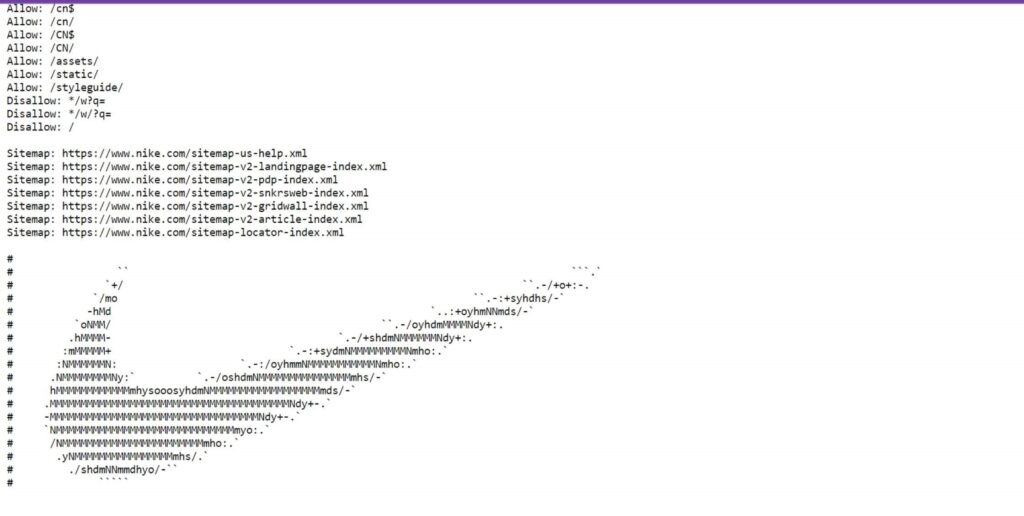
You can consider another website for robots.txt example.
From the above paragraph, you know how to find the robots.file of any website.
Once you are done with the syntax of robots.txt just save the Notepad file and put it into the directory location of your website.
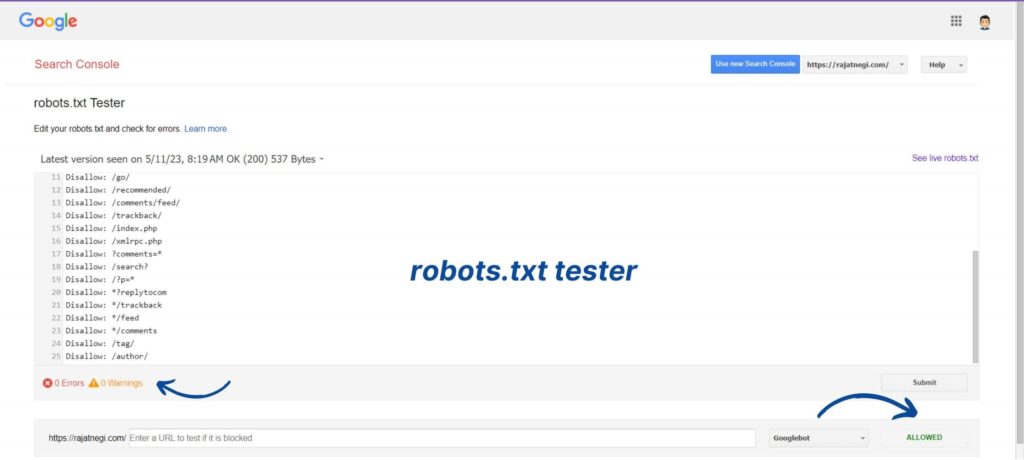
You can also refer to this guide which is by Google Itself.